Machine Learning
Machine Learning
Definition: Field of study that gives computers the ability to learn without being explicitly programmed.
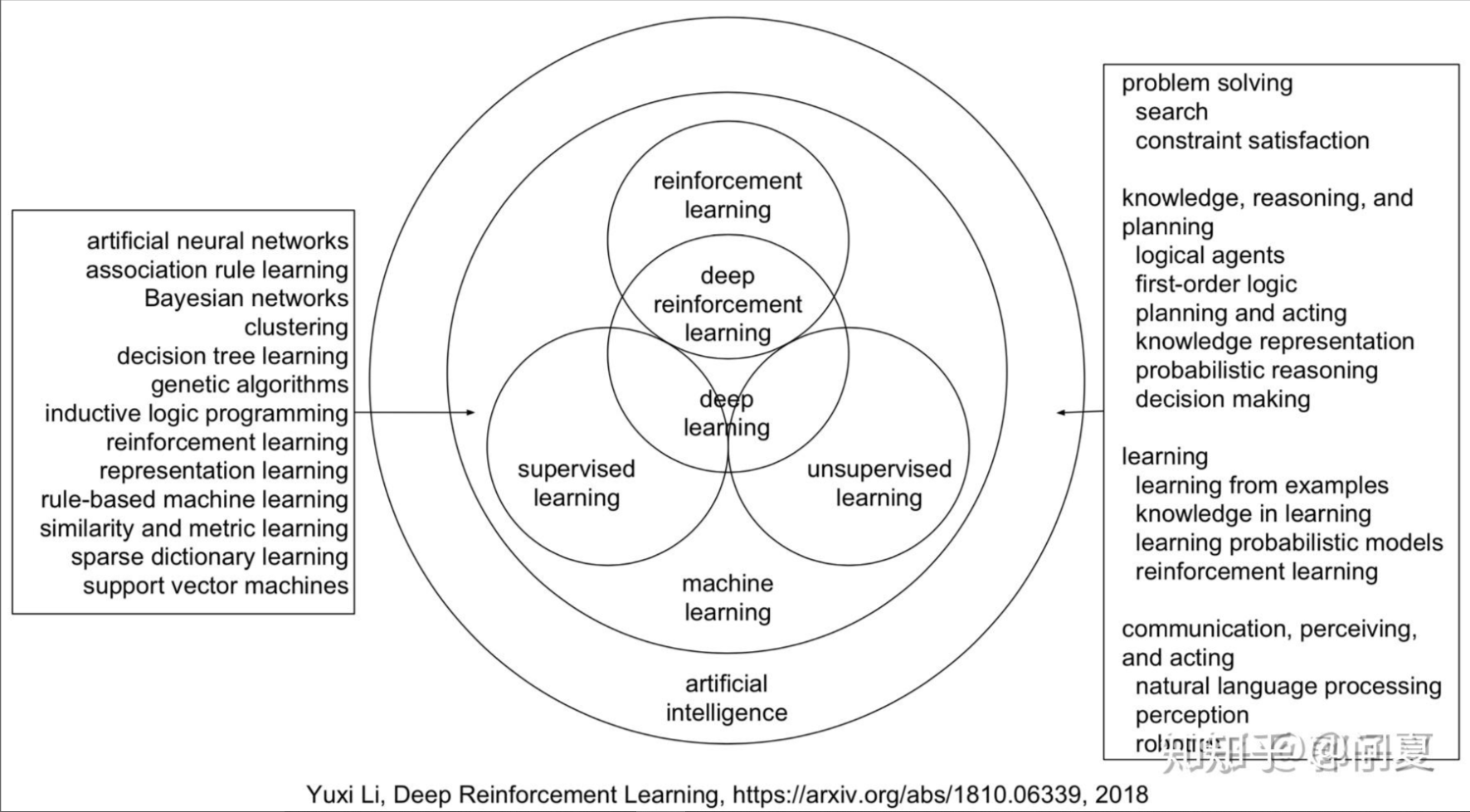
In general, there are three fields in machine learning, that is, supervised learning, unsupervised learning and reinforcement learning. Their relationships are as follow:
Supervised learning
Supervised learning is the most commonly used machine learning. It's definition is:
Supervised learning refers to algorithms that learn input to output mappings. The key of it is that you give the input(x) and the correct output(y) for the algorithms to learn. Then, the learning algorithms eventually learn to get the input alone and give a reasonably accurate prediction or guess of the output. In short, supervised learning learns from data labeled with the "right answers".
There are generally two types of supervised learning, regression and classification.
Regression
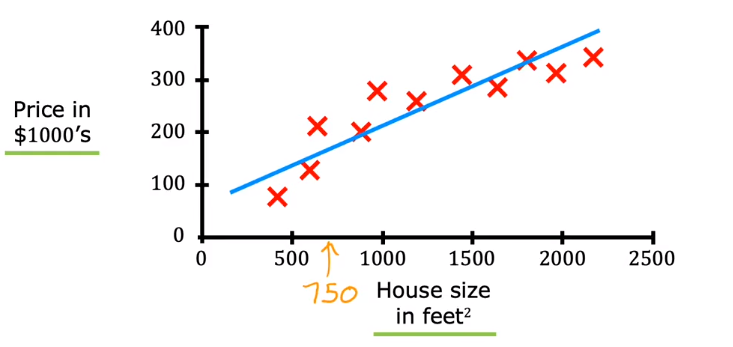
Regression is a kind of supervised learning that predicts a number, so its output contains infinitely many possible results. For example, housing price prediction:
Classification
Classification is a kind of supervised learning that predicts categories which can be number or non numeric, so its output just contains a small number of results. For example, breast cancer detection:

Both regression and classification can have more than one inputs.
Unsupervised learning
Unsupervised learning's definition:
Unsupervised learning refers to algorithm that find something interesting in unlabed data. In unsupervised learning,the algorithms figure out all by themselves what's interesting or what patterns or structures might be in the dataset. Data only comes with input(x), but not output labels(y). Algorithm has to find structure in the data.
There are generally three types of unsupervised learning, clustering, anomaly detection and dimensionality reduction.
Clustering
Clustering is a kind of unsupervised learning that groups data into different categories by any standard. For example, grouping customers:
Anomaly detection
Anomaly detection is a kind of unsupervised learning that finds unusual data points. It is very useful in financial system.
Dimensionality reduction
This kind of unsupervised learning compresses data using fewer numbers.
Reinforcement learning
Reinforcement learning is an new field in machine learning that has not yet been well applied but has a promising future.
Tool
Jupyter notebook
Jupyter notebook is the default environment that most researchers use to code up and experiment.
PyTorch
see PyTorch.
Tensorflow
See Tensorflow.
NumOy
See NumPy.
Scikit-learn
See Scikit-learn.
Terminology
- Training set: Data used to train a model.
- Test set: Data used to evaluate a model.
Notation
- ${x}$ = "input" variable or feature;
- ${y}$ = "output" variable or "target" variable;
- ${m}$ = number of training examples;
- $(x, y)$ = a single training example;
- $(x^i,y^i)$ = $i^{th}$ training example;
- $x_j$ = $j^{th}$ feature;
- $n$ = number of features;
- ${\vec{x}^{(i)}}$ = features of $i^{th}$ training example.
- $x_j^{(i)}$ = value of feature $j$ in $i^{th}$ training example ($x$ can also be $\vec{x}$).