Machine Learning Development Process
Full cycle of ML
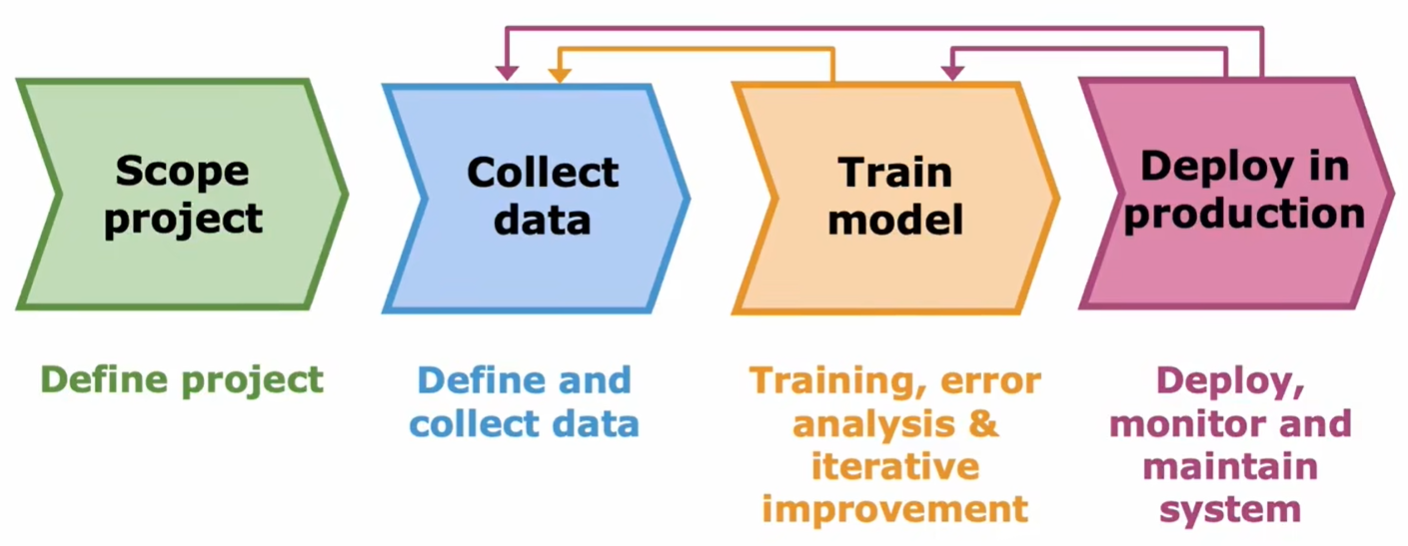
When developing a machine learning project, these are the four assignments we need to conduct.
Scope project
The step defines the purposes of the machine learning project and the functions it should implement.
Collect data
In this step, we define the data we need and try to collect as much data as we can. However, instead of adding data of all types, it is advisable to focus on adding more data of the types that error analysis has indicated it migh help.
Data augmentation
Data augmentation is a useful technique used especially for image and audio data.It creates new training examples by modifying existing training examples.For image data, we can distort the image and for audio data, we can add some noise.However, the type of noise or distortions we add to the set must be meaningful, that is, they should not be purely random but should be pertinent.
Data synthesis
Unlike data augmentation, data synthesis creates brand new examples. This method is used most for CV.
Transfer learning
Transfer learning is a research problem in machine learning that focuses on applying knowledge gained while solving one task to a related task. For example, knowledge gained while learning to recognize cars could be applied when trying to recognize trucks. This method is especially useful when we do not have enough data or computing power to train a large neural network.
When using transfer learning:
- Download neural network parameters pretrained on a large dataset with the same input type (e.g., images, audio, text) as our application;
- Change the output layer and further train (fine tune)the network on our own data.
When fine tuning, we can only train output layers parameters when our training set is small or we can train all parameters when our training set is large enough.
The reason why tranfer learning works is that in the hidden layers of a pretrained model, they have learnt something (maybe a subset of our target). Therefore, using the parameters of a pretrained model will make our model start from a better place.
AI = Code + Data. When models or algorithms are good enough, focusing on data can be an efficient way to help learning algorithms improve their performance.
Train model
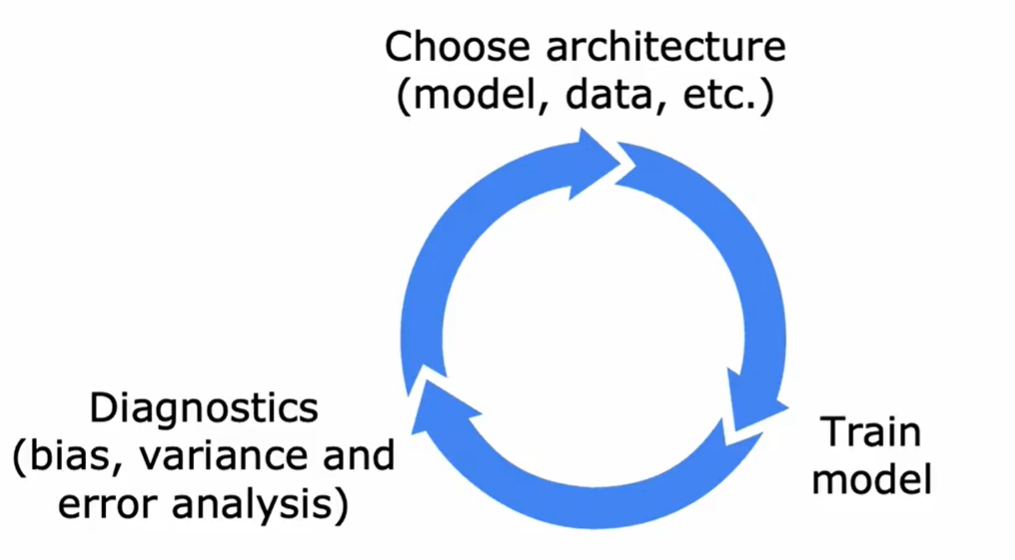
Depending on bias, variance and error analysis, we may need to modify the model or collect more data.
Deploy in production
A common structure of an application that uses machine learning models is as follows:
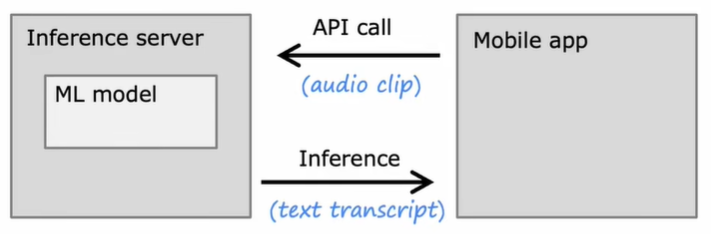
The job of inference server is to call the trained model in order to make predictions.Inference server expose its API to mobile app. Mobile app just need to call API and wait for the prediction from inference server.
In this step, if the app does not work well, we may need to retrain the model or collect more data.