Paper001: Dataset Condensation with Gradient Matching
数据蒸馏
当前最先进的深度学习技术几乎都采用的是大数据训练大模型的方式。这样的方式能够得到如GPT-4等具有远超我们想象的性能的大模型,但是其训练的算力和内存开销是一般人难以承担的。
数据蒸馏(Dataset Distillation)是解决这种问题的一种技术。它以学习的方式,从初始的大训练数据集(the original large training set)中(e.g. MNIST, CIFAR10等经典的数据集)获得一个更小的合成数据集(synthetic set)。这个合成数据集的数据量可能只有原数据集的1%,但是,用该数据集训练得到模型的性能可以达到用原数据集训练得到模型性能的80%~100%,同时也能具有不输于原模型的泛化性能。下图显示了数据蒸馏的目标。需要注意的是,原数据集与合成数据集训练的网络是一模一样的,测试集中的数据也是一模一样的,不同的只是训练集中的数据。
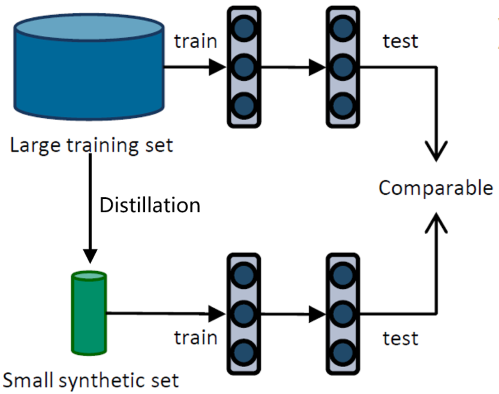
除了所用的训练集不同外,合成集训练得到的模型和原集得到的模型几乎一致(实际的模型参数可能不同)。因此,以后再用同样的数据集训练模型时,完全可以使用更小、训练速度更快的合成数据集,而测试和部署时模型的输入依旧为未经合成处理的数据。

数据缩合
本篇论文发表于ICLR 2021,第一作者是Dr. Bo Zhao。论文中用到的数据蒸馏方法称“数据缩合”(Dataset Condensation)。其最基本的设想是:合成集模型要想获得可与原集模型相媲美的性能和泛化能力,只要两个集合训练出的模型具有相似的模型参数就好了,即:对于原数据集$\mathcal{T}=\left\{(x_i,y_i)\right\}| _{i=1} ^\mathcal{|T|}$,其中$x\in\mathbf{R}^d$,是单一样本的特征,$y\in\left\{0,1,...,C-1\right\}$,是单一样本的标签,$C$是类别个数;对于合成数据集$\mathcal{S}=\left\{(s_i,y_i)\right\}| _{i=1} ^\mathcal{|S|}$,其中$s\in\mathbf{R}^d$,是单一合成样本的特征,$y\in\left\{0,1,...,C-1\right\}$,是单一合成样本的标签,其类别和数量与原标签一致,它们分别独立训练相同网络的最优化模型参数分别为:
$$
\begin{align*}
\theta ^{\mathcal{T}}&=\arg\min _{\theta}\mathcal{L ^T}(\theta)\tag{1}\\
\theta ^{\mathcal{S}}&=\arg\min _{\theta}\mathcal{L ^S}(\theta)\tag{2}
\end{align*}
$$
其中,$\mathcal{L}$是代价函数(Cost Function),两个训练集采用相同的代价函数,而$\theta ^{\mathcal{T}}$和$\theta ^{\mathcal{S}}$则分别是网络达到最优状态时的模型参数,两者相似,即它们之间的距离要尽可能地小:
$$
\min _\mathcal{S}D(\theta ^{\mathcal{T}},\theta ^{\mathcal{S}})\quad \text{subject to} \quad \theta ^{\mathcal{S}}(\mathcal{S})=\arg\min _{\theta}\mathcal{L ^S}(\theta)\tag{3}
$$
其中$\theta ^{\mathcal{S}}$是$\mathcal{S}$的函数是因为我们期望找到这么一个合成集$\mathcal{S}$,使得由它训练得到的$\theta ^{\mathcal{S}}$能够满足$(3)$。训练开始时,我们一般会把$\theta ^{\mathcal{T}}$和$\theta ^{\mathcal{S}}$初始化为相同的值$\theta_0$,其中$\theta_0\sim P _{\theta_0}$。但是不同的$\theta_0$可能会得到不同的$\theta ^{\mathcal{T}}$,因此,更进一步地,我们希望不同$\theta_0$下距离的期望是最小的,于是$(3)$转变为:
$$
\min _\mathcal{S}\text{E} _{\theta_0\sim P _{\theta_0}} [D(\theta ^{\mathcal{T}} ({\theta_0}),\theta ^{\mathcal{S}} ({\theta_0}))]\quad \text{subject to} \quad \theta ^{\mathcal{S}}(\mathcal{S})=\arg\min _{\theta}\mathcal{L ^S}(\theta ({\theta_0})) \tag{4}
$$
一般情况下,给定$\theta_0$,$\theta ^{\mathcal{T}}$可以通过训练网络得到。此后,$\theta ^{\mathcal{T}}$便可用于训练$\mathcal{S}$,这包含两层的循环:
- 任意初始化一个$\mathcal{S}$集;
- 内层循环:根据给定的$\theta_0$和当前的$\mathcal{S}$,训练与$\theta ^{\mathcal{T}}$相同的网络,得到当前的$\theta ^{\mathcal{S}}$,此过程对应$(4)$的后一项;
- 外层循环:初始化内层循环的$\theta_0$,内层循环结束后,计算$\theta ^{\mathcal{T}}$和$\theta ^{\mathcal{S}}$之间的距离,得到梯度($\mathcal{S}$为自变量),更新$\mathcal{S}$,此过程对应$(4)$的前一项。
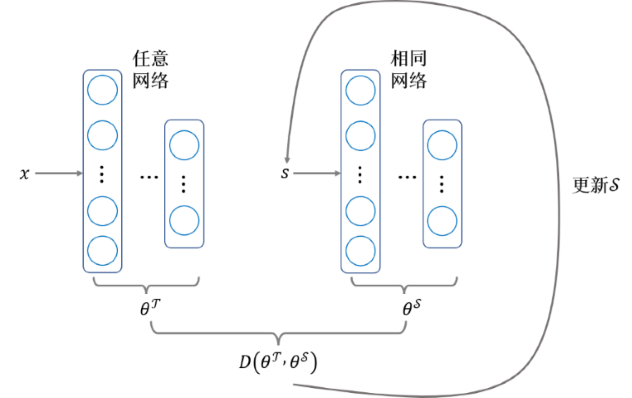
不难看出,每次内层循环都相当于重新训练了一个网络,这是很浪费算力的。然而在实际操作的过程中,我们并没有必要每次都训练出当前$\mathcal{S}$下最优的$\theta ^{\mathcal{S}}$,毕竟这只是个近似值。因此,实际上,我们采用用特定的优化算法优化了几步得到的$\theta ^{\mathcal{S}}$作为近似值即可,即:
$$
\theta ^{\mathcal{S}}(\mathcal{S})=\text{opt-alg} _{\theta}(\mathcal{L ^S}(\theta),\varsigma) \tag{5}
$$
其中$\varsigma$是优化(梯度下降)的次数,而$\text{opt-alg}$是任意的优化算法(e.g. adam, sgd, etc.),$\theta$是$\theta_0$的函数,此处为方便不写出,后面也是。
合成的是特征$\mathcal{s}$,不对labels进行合成操作。
梯度匹配
上面的数据缩合方法又称参数匹配法(Parameter Matching),即以让$\theta ^{\mathcal{S}}$逐渐逼近$\theta ^{\mathcal{T}}$的方式来训练得到$\mathcal{S}$。该方法有两个弊端:
- $\theta ^{\mathcal{T}}$与$\theta ^{\mathcal{S}}$之间可能相差很大且一个网络的模型参数空间很大,优化路径中可能存在若干局部最小值,因此难以达到最优解;
- 限定步数的$\text{opt-alg}$得到的参数过于不精确,但为了计算性能只能这么做。
最原始的数据蒸馏算法用的就是参数匹配法。数据蒸馏和数据缩合实际上是一回事,只不过数据缩合特指这篇文章所用到的蒸馏算法。
这篇论文提出的能解决上述问题的方法称梯度匹配(Gradient Matching),其核心思想在于:不仅让$\theta ^{\mathcal{T}}$和$\theta ^{\mathcal{S}}$最终的值相近,且遵循的优化路径也相近。于是式$(4)$就变成:
$$
\begin{align*}
\min _\mathcal{S}\text{E} _{\theta_0\sim P _{\theta_0}} [\sum\limits _{t=0} ^{T-1}D&(\theta _t ^{\mathcal{T}},\theta _t ^{\mathcal{S}})]\quad \text{subject to}\tag{6}\\
\theta ^{\mathcal{S}} _{t+1}(\mathcal{S})=\text{opt-alg} _{\theta}(\mathcal{L ^S}(\theta _t),\varsigma ^{\mathcal{S}}) \quad&\text{and}\quad \theta ^{\mathcal{T}} _{t+1}=\text{opt-alg} _{\theta}(\mathcal{L ^T}(\theta _t),\varsigma ^{\mathcal{T}})
\end{align*}
$$
其中$\varsigma ^{\mathcal{S}}$和$\varsigma ^{\mathcal{T}}$分别是$\mathcal{S}$和$\mathcal{T}$一次优化的梯度下降次数,$T$是迭代次数。整个式$(6)$表明,$\mathcal{S}$要使得整个迭代过程中的距离和最小,即$\mathcal{S}$要使得$\theta ^{\mathcal{T}}$与$\theta ^{\mathcal{S}}$几乎遵循相同的优化路径。每一次梯度下降,$\theta ^{\mathcal{T}}$与$\theta ^{\mathcal{S}}$的变化如下所示:
$$
\theta ^{\mathcal{S}} _{t+1} \leftarrow \theta ^{\mathcal{S}} _{t}-\eta_\theta\nabla_\theta \mathcal{L} ^{\mathcal{S}}(\theta _t ^{\mathcal{S}}) \quad\text{and}\quad \theta ^{\mathcal{T}} _{t+1} \leftarrow \theta ^{\mathcal{T}} _{t}-\eta_\theta\nabla_\theta \mathcal{L} ^{\mathcal{T}}(\theta _t ^{\mathcal{T}})\tag{7}
$$
其中$\eta_\theta$是学习率而其后续项为梯度。
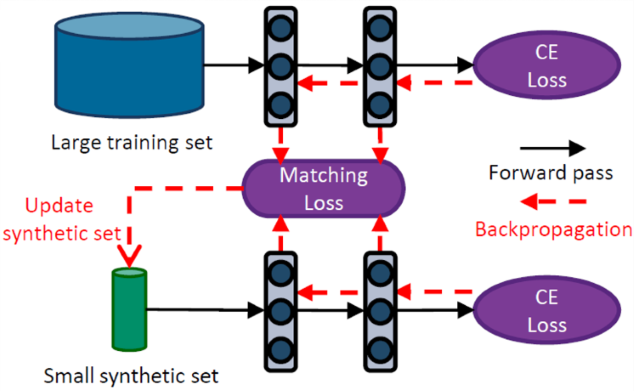
由于$\theta ^{\mathcal{T}}$与$\theta ^{\mathcal{S}}$均初始化为$\theta_0$,所以在计算距离$D(\theta _t ^{\mathcal{T}},\theta _t ^{\mathcal{S}})$时:
$$
\theta ^{\mathcal{S}} _{0}-\eta_\theta\nabla_\theta \mathcal{L} ^{\mathcal{S}}(\theta _0 ^{\mathcal{S}}) -(\theta ^{\mathcal{T}} _{0}-\eta_\theta\nabla_\theta \mathcal{L} ^{\mathcal{T}}(\theta _0 ^{\mathcal{T}}))=\eta_\theta\nabla_\theta \mathcal{L} ^{\mathcal{T}}(\theta _0 ^{\mathcal{T}})-\eta_\theta\nabla_\theta \mathcal{L} ^{\mathcal{S}}(\theta _0 ^{\mathcal{S}})\tag{8}
$$
因此,实际上我们只需要计算梯度的距离,并让其尽可能地小即可,于是式$(6)$又可转变为:
$$
\min _\mathcal{S}\text{E} _{\theta_0\sim P _{\theta_0}} [\sum\limits _{t=0} ^{T-1}D(\nabla_\theta \mathcal{L} ^{\mathcal{S}}(\theta _t ^{\mathcal{S}}),\nabla_\theta \mathcal{L} ^{\mathcal{T}}(\theta _t ^{\mathcal{T}}))] \tag{9}
$$
即,只要梯度下降的方向相近即可。
实际上,$\varsigma ^{\mathcal{S}}$和$\varsigma ^{\mathcal{T}}$由优化算法决定,不同的优化算法,在处理完所有训练数据后,梯度下降的次数不同。$\theta _t ^{\mathcal{T}}$和$\theta _t ^{\mathcal{S}}$实际上值相同,因为实际训练时分两个阶段:训练并更新$\mathcal{S}$和训练并更新$\theta_t$,而$\mathcal{S}$和$\mathcal{T}$经过的都是相同的网络,所以$\theta_t$也是一样的。$\theta_t$的梯度下降使用的数据是$\mathcal{S}$,这也在一定程度上造成了该方法的误差。
由于梯度是向量,而对于多参数的梯度下降,重要的是下降的方向,因此距离$D$采用两个向量的余弦距离,而不是欧式距离:
$$
\begin{align*}
D(\mathbf{A},\mathbf{B})
&=1-cos<\mathbf{A},\mathbf{B}>\\\
&=1-\frac{\mathbf{A}\cdot\mathbf{B}}{||\mathbf{A}||\space||\mathbf{B}||}\tag{10}
\end{align*}
$$
重要代码
以下只是对文中代码的简单实现(并不能运行),具体代码详见文章提供的开源部分Dataset Condensation。

1 | # 参数定义 |
实验设计
实验主要分为三个部分:
- 与现有核心集选择法和数据蒸馏法的性能比较;
- 缩合数据的泛化性分析;
- 缩合数据的数量与性能分析。
采用的数据集分别为MNIST,SVHN,FashionMNIST和CIFAR10,网络结构有六种:MLP,ConvNet,LeNet,AlexNet,VGG-11和ResNet-18。每种结构5次重复实验,在训练$\mathcal{S}$的过程中,当k达到一定次数时,会用$S$去训练20个随机初始化的网络以分析训练效果。
与现有方法性能比较
文中统一采用ConvNet作为所有方法的训练网络,与DC相比较的核心集选择法有Random,Herding,K-Center和Forgetting,以往的数据蒸馏方法则是DD(Dataset Distillation)。
泛化性分析
这部分实验分析的是某一网络训练出来的合成数据$\mathcal{S}$用于训练其他网络能否达到较好的性能。作者对6种网络进行了一一组合。
缩合数据数量
这部分分析的是每个类别生成几张缩合图片合适,作者分析了1,10和50三种情况,结果当然是越多效果越好。
应用场景
作者对数据缩合可能存在的两大应用场景进行了分析。
持续学习
持续学习(Continual Learning)是一种将旧任务学习的知识应用到新的任务上、同时在旧任务上的表现不会出现太大的损失的机器学习方法。本质上是基于旧有的模型训练面向新任务的模型,使得最终的模型在新旧任务上都能表现得很好。相比于普通的数据,数据缩合后的合成数据有效信息更多,很适合持续学习。
神经网络架构检索
选择合适的神经网络架构需要训练大量的模型,而数据量更小的合成数据显然能大大地降低训练的算力和存储开销。