Per-Layer Embedding
笼统地来说,所有的深度学习模型都只有两个部分:特征输入以及特征交互。其中特征输入一般只存在于最底层,如image的整张图片、text经tokenization后的embedding以及推荐系统中的各类用户或上下文或物品特征。基本上除了推荐会做很多额外的显式特征交叉与处理,其他的输入类型对特征输入都尽量保持精简;而特征交叉(此处为广义的隐式特征交叉)即为后续的所有网络结构。
换句话说,即便是在当今的大模型浪潮下,模型的所有“外部信息”输入都是在最底层完成的,剩余的模型结构都在做特征抽取或交叉。不过2025年开始有了一些把底层输入分散到各个层的尝试,比较有代表的是Google的PLE以及RWKV的DeepEmbed。
Gemma PLE
其中,PLE更多地可被视为一种硬件加速、缓存策略。原本在最底层我们可能需要读取4096维的token embedding,但有了PLE,可能就可以底层读取2048维,剩下的在每层需要的时候再读。这带来的最大好处是这些后读取的embedding可以被存到cache中,从而极大地缓解访存压力,至于模型性能的提升Google并没有公布。
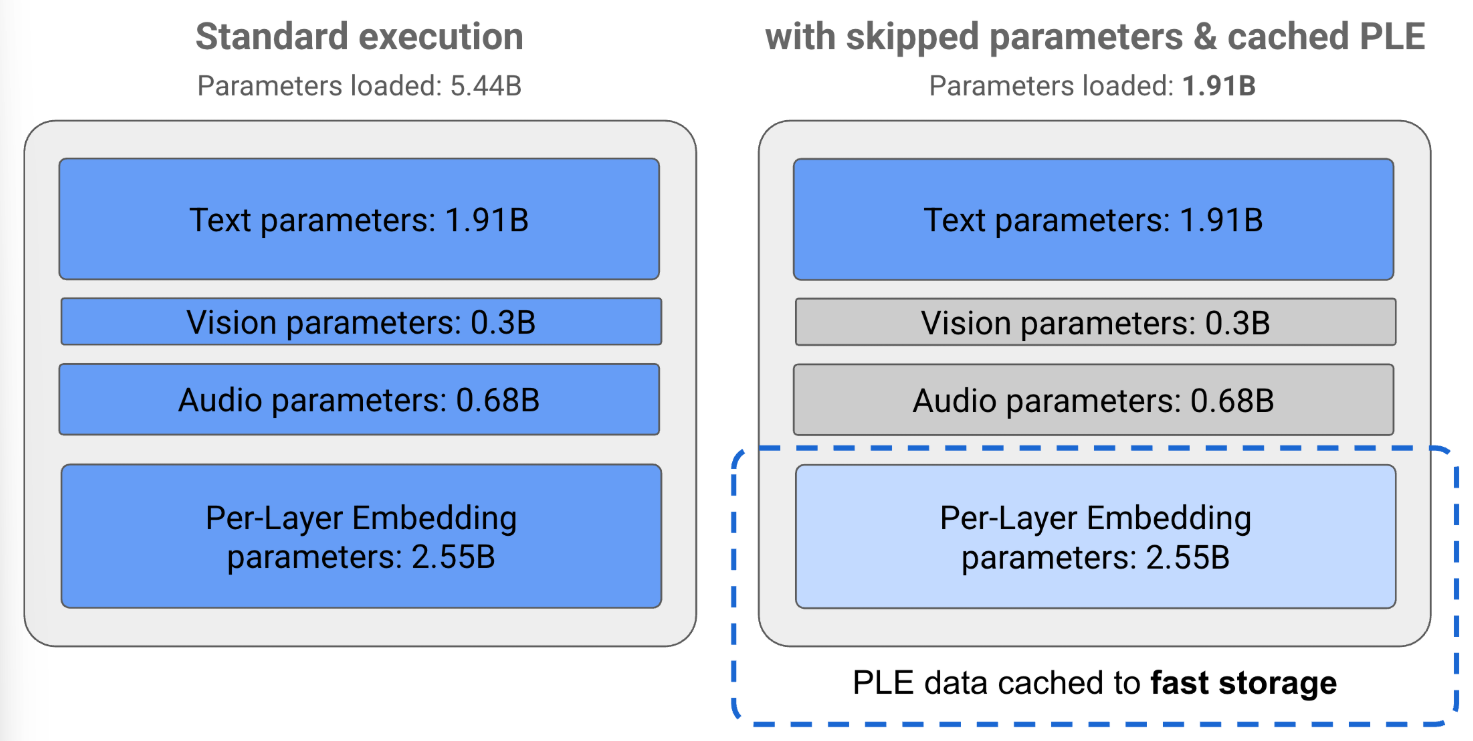
RWKV DeepEmbed
而DeepEmbed除了有着PLE相似的加速效果外,还给出了其对训练的影响: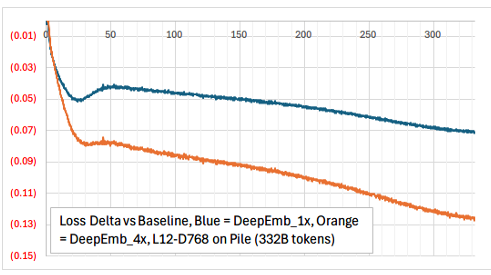
并且整体的实现也十分简单,只需将DeepEmbed的编码(应该还会经过一个Linear层)与FFN(RWKV用的是ReLuSq FFN,即ReLu激活函数+平方)哈达曼积即可:
1 | // ReLuSq FFN |
1 | // ReLuSq FFN + DeepEmbed |
这里将第一层Linear称为key,第二层称为value其实也体现了将MLP当做一个“字典”、“知识库”的观点。
DeepSeek Engram
Engram与前两者存在一定的相似,但“故事”以及完整性显然要更好一点。从大的方向来说,LLMs在做的就是两件事情:推理(reasoning)以及知识检索(knowledge retrieval),并且很大程度地依赖FFN(MoE或MLP)完成。但Attention是序列自回归的,因此在无外挂知识库的情况下,它需要很多计算才能逐步激活所需要的知识,作者认为这是对算力的浪费。因此,Engram就是这么一个内挂的知识库,将一些“固定搭配”作为新的token,赋予模型查表的能力,让FFN更多地负责推理(如,将“马化腾”作为一个固定搭配,那么模型可能就不需要那么多的激活参数计算这三个字是怎么关联在一起的,而可直接将其视作人名)。
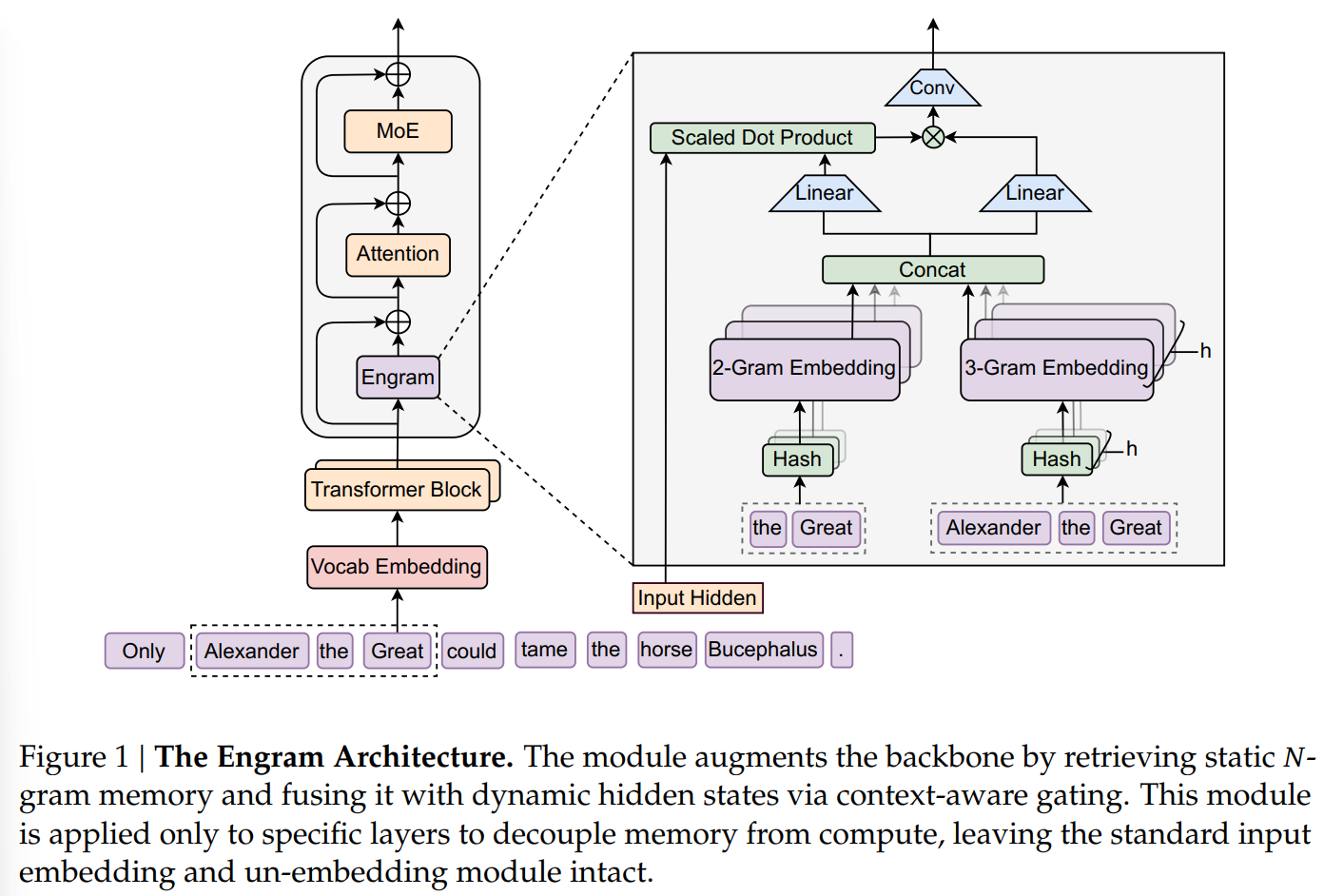
因为Engram是开源的,所以这次直接对着代码开搞!GITHUB
- 因为是在选择的一些TransformerBlock(代码中为第二层与第十六层)中嵌入了Engram,所以整体还是Embedding层、n个TransformerBlock以及最后的Linear投影:
1
2
3
4
5LLM = [
nn.Embedding(vocab_size, hidden_size),
*[TransformerBlock(layer_id=layer_id) for layer_id in range(num_layers)],
nn.Linear(hidden_size, vocab_size)
] - 同时,由于Engram是动态生成的,所以每个TransformerBlock的输入除了hidden_embedding外,还要额外地输入原始token_ids:
1
hidden_states = TransformerBlock(input_ids, hidden_states) // [batch, length, head, head_dim]
- 在TransformerBlock中,对有Engram的块,先执行Engram:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class TransformerBlock(nn.Module):
def __init__(self, layer_id):
...
self.engram = None
if layer_id in engram_layer_ids:
self.engram = Engram(layer_id=layer_id)
def forward(self, input_ids, hidden_states):
if self.engram is not None:
hidden_states = self.engram(hidden_states, input_ids) + hidden_states
...
Attention_Step
...
FFN_state
...
return hidden_states - 在
Engram中,如原文所述,由retrieval和fusion两步组成,简单地来说就是一个简化的Tokenizer+简化的Attention&Conv:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48class Engram(nn.Module):
def __init__(self, layer_id):
// retrieval
self.hash_mapping = NgramHashMapping(...)
// 有个写法之前没见过,记录一下;即将元素个数不同或相同的List[List]展开为一个List,
// 如[[1, 2, 3], [1, 2]]
self.multi_head_embedding = MultiHeadEmbedding(
list_of_N = [x for y in self.hash_mapping.vocab_size_across_layers[self.layer_id] for x in y],
D = engram_cfg.n_embed_per_ngram // engram_cfg.n_head_per_ngram,
)
// fusion
self.short_conv = ShortConv(...)
engram_hidden_size = (self.max_ngram_size-1) * self.n_embed_per_ngram
self.value_proj = nn.Linear(engram_hidden_size,backbone_config.hidden_size)
self.key_projs = nn.ModuleList(
[nn.Linear(engram_hidden_size,backbone_config.hidden_size)
for _ in range(backbone_config.hc_mult)]
)
self.norm1 = nn.ModuleList([nn.RMSNorm(backbone_config.hidden_size)
for _ in range(backbone_config.hc_mult)])
self.norm2 = nn.ModuleList([nn.RMSNorm(backbone_config.hidden_size)
for _ in range(backbone_config.hc_mult)])
def forward(self, hidden_states, input_ids):
"""
hidden_states: [batch, length, head, head_dim]
input_ids: [batch, length]
"""
// retrieval
hash_input_ids = torch.from_numpy(self.hash_mapping.hash(input_ids)[self.layer_id])
// 2-ngram&3-ngram embedding平铺
embeddings = self.multi_head_embedding(hash_input_ids).flatten(start_dim=-2)
// fusion
gates = []
for hc_idx in range(backbone_config.hc_mult):
key = self.key_projs[hc_idx](embeddings)
normed_key = self.norm1[hc_idx](key)
query = hidden_states[:,:,hc_idx,:]
normed_query = self.norm2[hc_idx](query)
gate = (normed_key * normed_query).sum(dim=-1) / math.sqrt(backbone_config.hidden_size)
gate = gate.abs().clamp_min(1e-6).sqrt() * gate.sign()
gate = gate.sigmoid().unsqueeze(-1)
gates.append(gate)
gates = torch.stack(gates,dim=2)
value = gates * self.value_proj(embeddings).unsqueeze(2)
output = value + self.short_conv(value)
return output - Retrieval_Step分3步,分别为Tokenizer Compression、Multi-Head Hashing、Multi-Head Embedding:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97******
Tokenizer Compression
理论上,2-gram有vocab_size*(vocab_size-1)个新的token,但这么多token肯定是不可能用在实际的模型中的,
因此需要对这些组合进行压缩,整个Retrieval_Step干的都是这件事情。Compression是第一步,即把一些同义的
组合归为一个token,如大小写(`apple`与`Apple`)、前空格(`apple`与` apple`)、后空格(`apple`
与`apple `)等
******
class NgramHashMapping:
def hash(self, input_ids):
"""
compressed_tokenizer:一系列的转换规则对token进行标准化,如原本A的idx为65,a为97,
compressed_tokenizer将A的idx修改为97
"""
input_ids = self.compressed_tokenizer(input_ids)
******
Multi-Head Hashing
此处哈希同样是为了减少n-gram的组合数,因为原本的nn.Embedding中idx和embedding就可以视为一个一一
对应的哈希。因此此处的哈希是为了将多个n-gram token映射为一个组,即在Engram的一个新token实际代表
了多个n-gram组合。这样做的最大问题是组合和新token无法一一对应了,那最终学出来的embedding意义就很
模糊。文中给的解决方法是Multi-Head,每个Head有自己的EmbeddingTable,用多个哈希函数将一个n-gram
组合映射到不同的token中,最后将所有Head的Embedding凭借起来作为该组合的Embedding。文中从哈希碰撞
的角度解释,但我觉得应该从保证每个组合token唯一性的角度解释。不过直接用vq-vae学一个Codebook会不
会更好?
在文中的Multi-Head情况下,每个Head的vocab_size由预定义的下限开始(代码中为129280*5),顺序地
找大于下限的下一个质数。
如何映射?代码中的实现方式是:先shift组成多元组,对max_ngram_size=3,ids=[1, 2, 3, 4, 5]得到
的为:[1, 2, 3, 4, 5], [padding_idx, 1, 2, 3, 4], [padding_idx, padding_idx, 1, 2, 3];
紧接着2-gram:[1, 2, 3, 4, 5]与[padding_idx, 1, 2, 3, 4]异或;3-gram:[1, 2, 3, 4, 5]、
[padding_idx, 1, 2, 3, 4]、[padding_idx, padding_idx, 1, 2, 3]三者异或,最后每个Head简
单的取模哈希。
******
hash_ids_for_all_layers = {}
for layer_id in self.layer_ids:
hash_ids_for_all_layers[layer_ids] = self._get_ngram_hashes(input_ids,
layer_id=layer_id)
return hash_ids_for_all_layers
def _get_ngram_hashes(self, input_ids, layer_id):
x = np.asarray(input_ids, dtype=np.int64)
B, T = x.shape
multipliers = self.layer_multipliers[layer_id]
def shift_k(k: int) -> np.ndarray:
if k == 0: return x
shifted = np.pad(x, ((0, 0), (k, 0)),
mode='constant', constant_values=self.pad_id)[:, :T]
return shifted
base_shifts = [shift_k(k) for k in range(self.max_ngram_size)]
all_hashes = []
// max_ngram_size = 3,因此只有2-gram以及3-gram
for n in range(2, self.max_ngram_size + 1):
n_gram_index = n - 2
tokens = base_shifts[:n]
mix = (tokens[0] * multipliers[0])
for k in range(1, n):
mix = np.bitwise_xor(mix, tokens[k] * multipliers[k])
num_heads_for_this_ngram = self.n_head_per_ngram
// vocab_size_across_layers为大于129280*5的顺序head个质数
head_vocab_sizes = self.vocab_size_across_layers[layer_id][n_gram_index]
for j in range(num_heads_for_this_ngram):
mod = int(head_vocab_sizes[j])
head_hash = mix % mod
all_hashes.append(head_hash.astype(np.int64, copy=False))
return np.stack(all_hashes, axis=2)
******
Multi-Head Embedding
比较简单,因为每个Engram层、每个Head的vocab大小是不变的,因此用一个Embedding表+offset区分即可
******
class MultiHeadEmbedding(nn.Module):
def __init__(self, list_of_N: List[int], D: int):
super().__init__()
self.num_heads = len(list_of_N)
self.embedding_dim = D
offsets = [0]
for n in list_of_N[:-1]:
offsets.append(offsets[-1] + n)
self.register_buffer("offsets", torch.tensor(offsets, dtype=torch.long))
total_N = sum(list_of_N)
self.embedding = nn.Embedding(num_embeddings=total_N, embedding_dim=D)
def forward(self, input_ids: torch.Tensor) -> torch.Tensor:
shifted_input_ids = input_ids + self.offsets
output = self.embedding(shifted_input_ids)
return output - Fusion_Step比较简单:head-wise的ngram embedding投影,然后与hidden_states head-wise内积得到门控值,最后接一个序列维度的一维卷积。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// fusion
gates = []
for hc_idx in range(backbone_config.hc_mult):
key = self.key_projs[hc_idx](embeddings)
normed_key = self.norm1[hc_idx](key)
query = hidden_states[:,:,hc_idx,:]
normed_query = self.norm2[hc_idx](query)
gate = (normed_key * normed_query).sum(dim=-1) / math.sqrt(backbone_config.hidden_size)
gate = gate.abs().clamp_min(1e-6).sqrt() * gate.sign()
gate = gate.sigmoid().unsqueeze(-1)
gates.append(gate)
gates = torch.stack(gates,dim=2)
value = gates * self.value_proj(embeddings).unsqueeze(2)
output = value + self.short_conv(value)
return output
总的来看比PLE和DeepEmbed要更具可解释性,但本质上是一个聚类+查表,而现在这种哈希形成的聚类内部好像没什么相关性,我还是觉得可能用类似vq-vae的方式学习聚类embedding会比较好。