Ranking Stage Scaling
现行的推荐系统最核心的就三个阶段:召回-排序-混排。召回阶段的LLMs叙事是生成式召回,但SID或者Codebook等聚类型Token即便可NTP地生成,在聚类内以及聚类间总归还是需要有个排序的,因此排序模型仍然必不可少。排序阶段的LLMs叙事是特征Token化、参数Scaling,全面对齐LLMs以更好地利用大模型领域的进展。混排则更是一个典型的序列List-wise建模场景,不过目前暂未看到与Scaling相关的进展。
排序阶段的Scaling要向LLMs看齐,最重要的一步为Tokenization,即如何将各种输入特征组织为一个个的Token以形成一个矩阵,从而分别在行列维度进行交互。对于这点,OneTrans总结地很好:
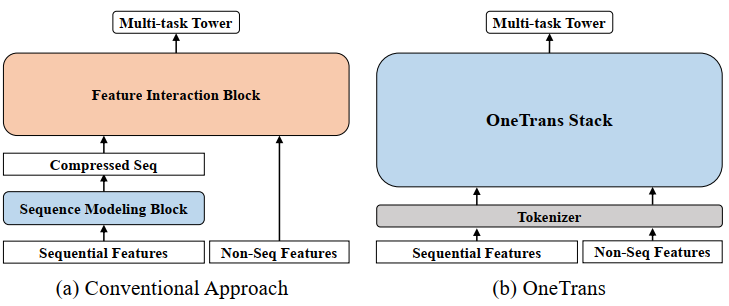
其中,前者(记为一类范式)一般通过Target-attention将二维的序列特征压缩为一维,和非序列特征拼接后再Token化;而后者(记为二类范式)则全面地保留二维序列,单独将非序列特征Token化,形成两类异质的Token(序列&非序列),最极端的情况下,只用非序列Token对序列Token做Attention,则此类范式可被视为一个超大的Target-attention。
RankMixer&TokenMixer
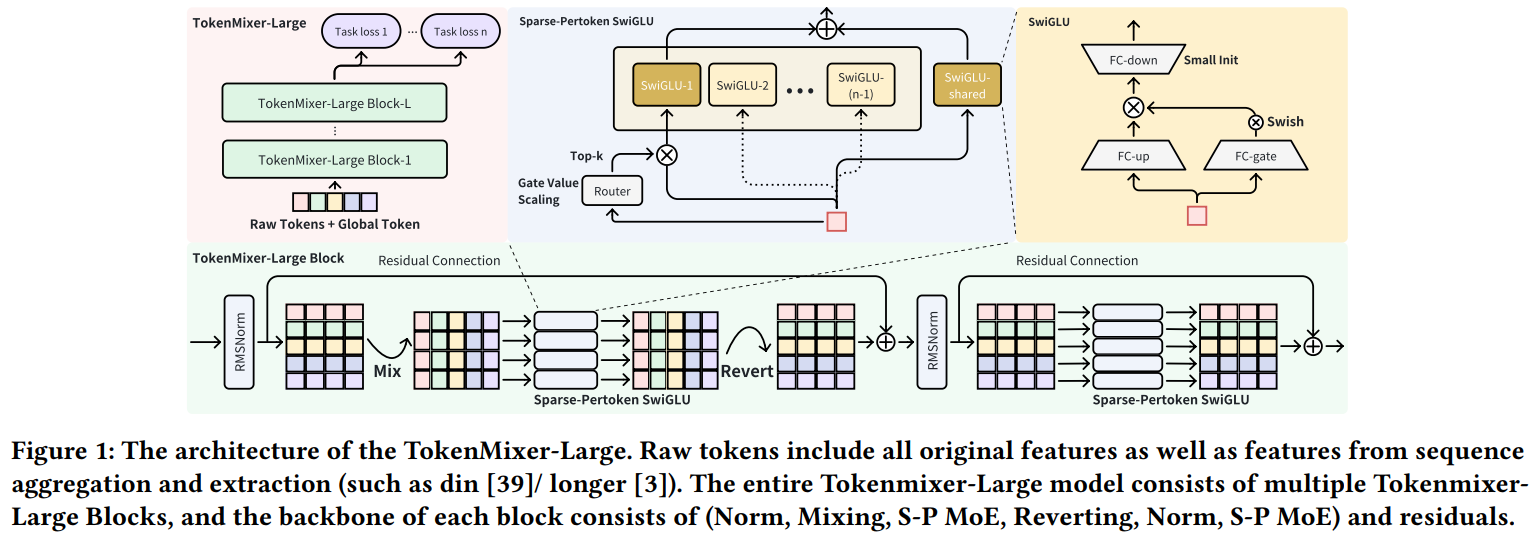
RankMixer和TokenMixer属于一类范式。相比RankMixer,TokenMixer主要是在Mixup中重新加入了映射参数,并将MLP更改为Gated-MLP。
OneTrans
OneTrans是更接近LLMs的二类范式,本质上相当于把所有的非序列特征当作了一个超大的Target。
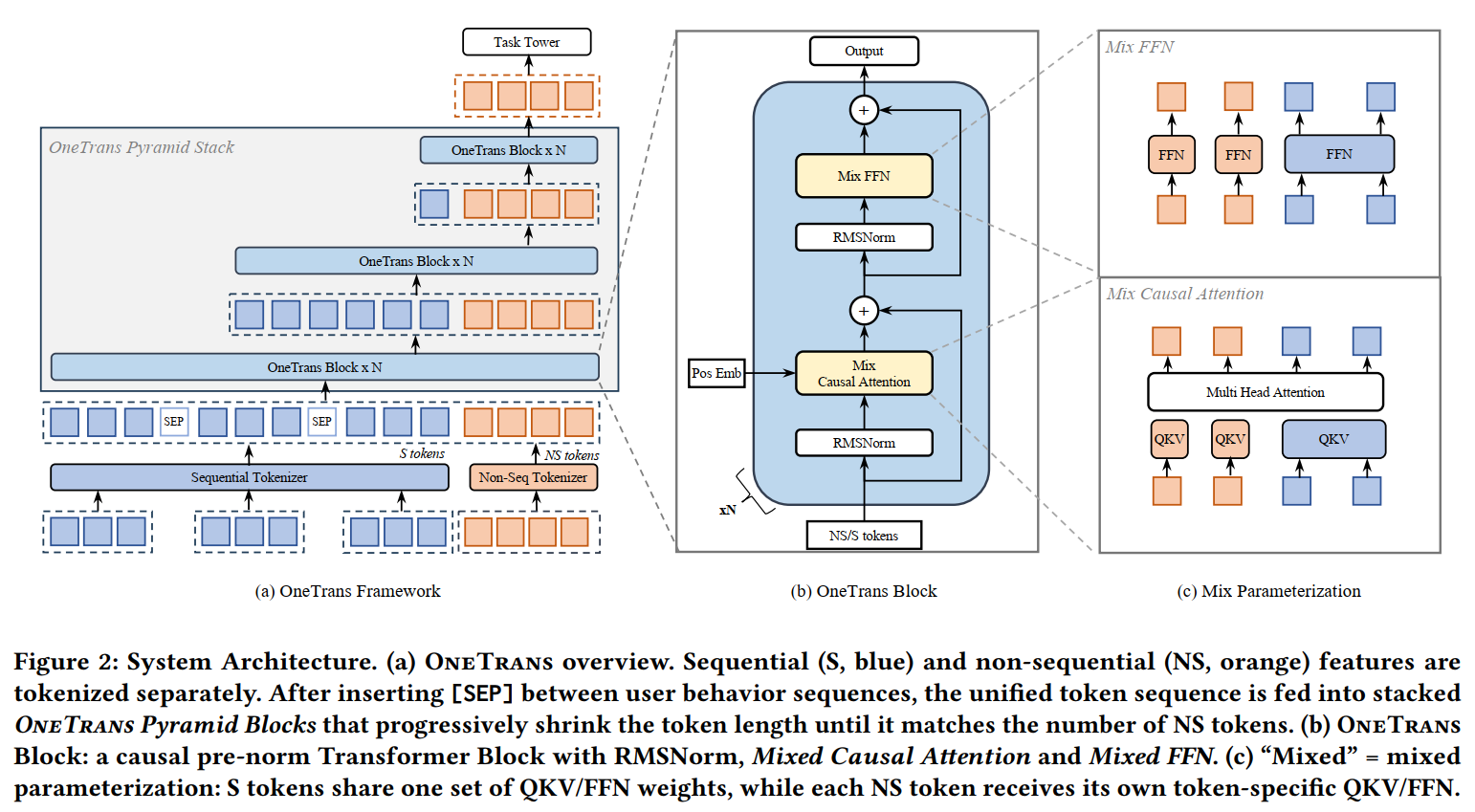
其要点为:
- Token的组织方式。序列Token在前,非序列Token在后。序列Token又由多个子序列Token组成:按时间顺序的全生命周期序列;按行为类型的序列,如购买序列、购物车序列等,其中,心智更强、更直接影响GMV的放在前面,如购买序列;不同的子序列用Token[SEP]分割;
- 参数的组织方式。序列Token共享一套QKV、FFN,非序列Token则每个Token一套QKV、FFN。
- 逐层的序列压缩。整体为完全的Causual-attention,这使得后面的Token聚合了前面Token的信息,因此OneTrans采用了逐层缩短Query的方式来压缩序列长度,如在某层中,KV为全序列,Q只为后一半序列,那么经过该Block的交互后,整体序列长度减半。最终只会剩下非序列Token,然后Mean-pooling过各种二分类任务。
线上Serving时,序列Token可KV cache,非序列Token因有各种Context或计数特征需要实时计算。虽然文中的消融实验显示Full-attention和Causual-attention效果差不多,但非序列Token感觉用双向注意力更好?